
Introduction
Lumos RL Workspace is a modular reinforcement learning framework for legged locomotion, designed around the Lus and NIX humanoid robots. Built on Isaac Lab, it decouples policy development from specific simulators, supporting seamless integration with both Isaac Sim and MuJoCo. Key features include:
- Modularity & Flexibility – controllers are isolated from the simulator core, enabling easy extension and platform switching.
- Imitation-based Learning – with motion references and adaptive curricula, policies can capture natural, human-like movements.
- General Interfaces – velocity and style commands, reward terms, and robot-specific modules simplify adaptation to new robots.
- Evaluation & Benchmarking – standardized tests across terrains, tasks, and styles enable robustness, generalization, and sim-to-real studies.
In short, Lumos RL Workspace is a simulation-agnostic, extensible platform for advancing locomotion policy research and deployment.
Using this guide, you will be able to retarget human motions, train locomotion policies, and deploy them to the Lus2 and Nix1 humanoid robots.
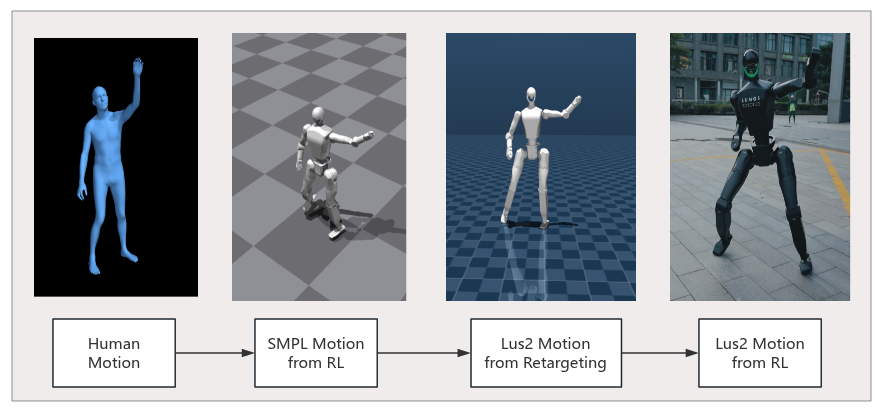
Figure: Motion Retargeting and Real-World Deployment
Projects
This chapter provides an overview of the two core projects in Lumos RL Workspace.Before diving into the details, the following diagram illustrates the relationship between the main components and their interactions:
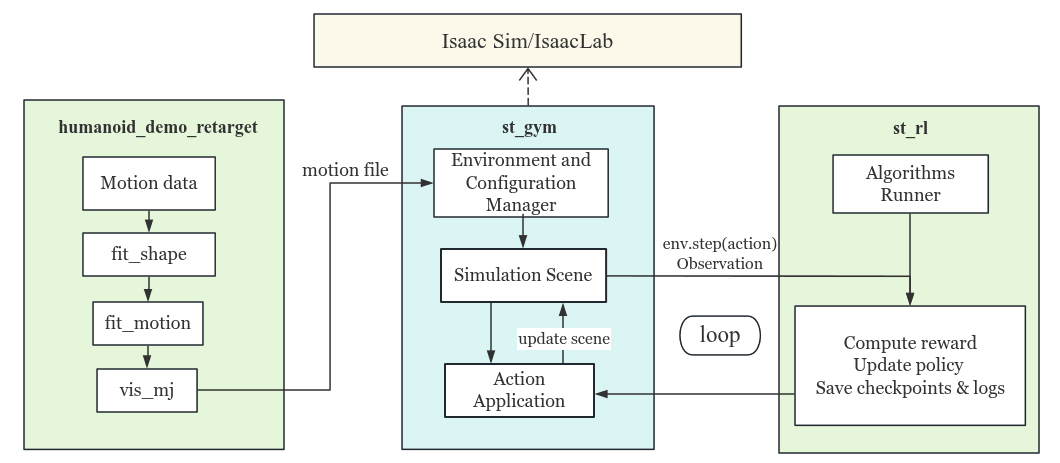
Figure: Project Relationship Diagram
Each project has its own subpage with two parts:
- Getting Started – Step-by-step guide for running demos and training policies.
- Concepts & Principles – Technical details, mathematical background, and design philosophy. Additional documentation will be added here progressively.
1. Trajectory Alignment
From human motions to Lus2 & Nix1
- Focus: Motion retargeting from human trajectories to Lus2 and Nix1.
- Provides tools for trajectory alignment and dataset preprocessing.
- Bridges between human motion datasets and robot-compatible policies.
Example Result Video: Retargeted human motion trajectory executed on Lus2.
.gif)
Figure: Comparison of Retargeted Motion (CMU_CMU_13_13_21_poses)
2. Policy Training and Play
- Focus: Reinforcement learning–based policy for humanoid robots.
- Framework: Built on st_gym (Isaac Sim–based environments) and st_rl (RL algorithms).
- Key Features:
- Multi-algorithm support: PPO, APPO, TPPO.
- Reference Motion Imitation: Optional imitation rewards in different modes with various trajectories.
- Configurable observation, action, and reward spaces for different tasks.
- Outcome: Trained control policies capable of robust humanoid motion in simulation.
Example Result Video: Trained motion policies on Lus2 in simulation.

Figure: Example Policy (Iteration: 20000, Motion File: dance1_subject2_fps25.pkl)
The policy path:st_gym/logs/st_rl/lus2_flat/2025-07-27_15-13-37/exported/policy.onnx